How CAPTCHA Works
February 15th, 2017 | By Jscrambler | 10 min read

CAPTCHA stands for Completely Automated Public Turing Test to Tell Computers and Humans Apart. Its goal is to check if a user (of an app or a website) is a human or a bot. It relies on specific traits that people have and machines don't. It's widely used in the web industry as a proactive defense against spam, bots, and DOS attacks.
You are familiar with this technology, even if you don't know its name.
Curious note: Although CAPTCHAs are developed to block automated bots, CAPTCHAs themselves are automated. As gatekeepers, they pop up in specific places on a website and pass or fail users after a quick and simple test.
How does CAPTCHA work?
CAPTCHA's roots date back to the beginning of the twentieth century when Alan Turing wanted to answer one question:
Are computers able to think like humans?
He set up a game of imitation, where an interrogator was obligated to ask two participants a series of questions. The participants were humans and machines.
The interrogator's challenge was to figure out which one was a human being. The interrogator was unable to see or hear them and needed to rely only on their responses. If the interrogator was unable to decide or decided wrongly, the machine passed the Turing test.
The goal of the CAPTCHA is to ask such a question or make such a challenge that computers are unable to deal with it. At the same time, it should be easy to answer for humans.
The scheme is simple.
You type some data or perform any other action, and then confirm it by passing a CAPTCHA test.
Text-based Captachas versus Image-based Captachas
The most common type of test is an image of a bunch of distorted letters. It uses the issue of computers not being able to think abstractly and "see" the world the way people do.
While humans are really sophisticated at processing visual data, computers lack those skills. When you look at the image, you can quickly read the pattern.
The brain of humans is constructed in such a way that it's always searching for a known pattern or shape. You know the paradox of seeing faces and shapes in trees and clouds, even if it's just an illusion. It's called pareidolia.
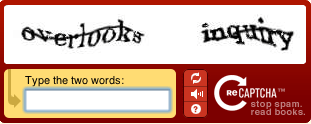
While you are easily able to read the above words and write them down, for computers, it's just a mass of zeros and ones.
Nevertheless, we have to remember how machines work.
CAPTCHA’s challenges shouldn't be limited to a fixed number. If they would, it would be easy to teach a computer which text corresponds to a given image. Therefore, many creators use sophisticated algorithms in order to generate their distorted texts randomly.
The creators of reCAPTCHA figured out another idea. They used the process of digitalizing books and asked users to decrypt the short pieces.
Due to evolving bot algorithms, text-distorted CAPTCHAs have become a lot harder to solve.
 While the first one (above) is quite readable, the second one could already cause some problems for someone without sharp eyesight (below).
While the first one (above) is quite readable, the second one could already cause some problems for someone without sharp eyesight (below). 
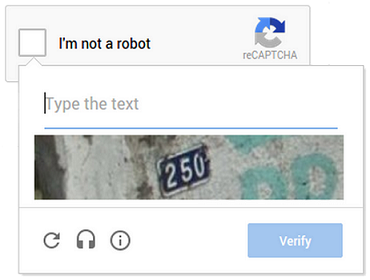
Therefore, a lot of developers tried to think of a new type of CAPTCHA. The result of their work was the select-images CAPTCHA.
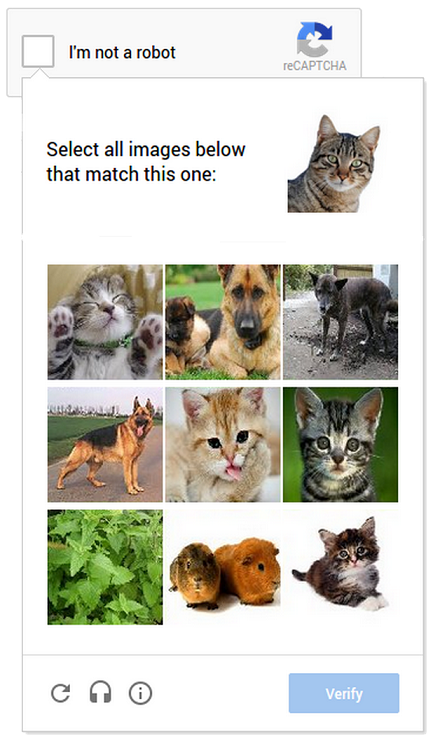
It relies on the same foundation, but it's just harder to solve for machines. And what's more important, it's easier to solve for humans.
The scheme is easy.
You have a collection of images and have to pick the ones that match the requirements. It's easy for you to pick the right ones. Computers, however, don't think like humans, and it's not so easy for them.
It relies on the classic computer vision problem of image labeling. Also, it's really mobile-friendly. It's easier to tap images corresponding to a clue than type a line of distorted text.
These approaches have their cons.
For machines, they’re hard to solve, but text-reading systems are also just algorithms. Thus, they encourage problems with reading CAPTCHAs and are treated like bots.
For blind people and people with different eye dysfunctions, it causes a technological barrier.
Sound-based Captchas
With barriers for blind people and people with different eye dysfunctions in mind, developers often add a sound CAPTCHA to their text-distorting solutions.
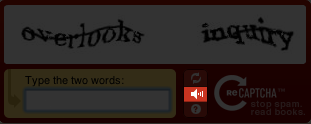 It works in a similar manner. The script adds background noise to the audio in order to make it harder for bots to solve. It has a small impact on humans, but it adds a lot of problems for voice-recognition programs.
It works in a similar manner. The script adds background noise to the audio in order to make it harder for bots to solve. It has a small impact on humans, but it adds a lot of problems for voice-recognition programs.
While all these solutions are perfect on paper, they can still be annoying and confusing. Therefore, Google introduced a new CAPTCHA (No CAPTCHA reCAPTCHA) that asks you only to check a box.
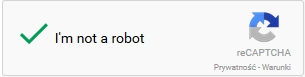
Why do we need a CAPTCHA?
Do we need a CAPTCHA because we no longer know if we are humans or robots? We hope not. The correct answer is that there are a lot of people out there who want to harm your website for different reasons:
Unfair competition
Malicious advertising
Malicious behavior
Just fun.
You can imply that it's not the majority of web users that are trying to exploit your system’s weaknesses, but the problem remains.
Denial of Service attack (DoS)
The simplest example is DOS (Denial of Service), which is a type of attack that is focused on making a resource unavailable.
The attacker sends a large number of requests to the server to make it incapable of returning results. It simply blocks your website.
Doing this attack individually, by a person, would be a horror. It would be exhausting, and simply impossible. You can't manually make an efficient number of requests, but computers don't get exhausted or bored. It's not a problem for them to make hundreds of requests every second.
CAPTCHA helps you identify such behaviors and block them.
Malicious advertising tactics
Another example is malicious advertising tactics. Every internet user is familiar with spam.
You receive tons of unwanted emails every day. It's easy to block one particular email, but it's hard to protect against unknown ones.
How do spammers get past the CAPTCHA?
If a spammer uses only one email account, we can easily block it. But imagine now that he or she hires a bot to use one of the free email providers (the one that doesn't use CAPTCHA). That way, it can set up a new account every several minutes and send spam content from different addresses.
Comments
A third example, more trivial, is comments.
Many websites, even small blogs, are fighting unwanted ads. Of course, we can turn a blind eye to one or two spam messages. Unfortunately, we often see hundreds of them.
It’s usual to find well-written content with a spam comments section. If you see a post with hundreds of the same messages (not related to the text), the owner probably does not use CAPTCHA.
Even for real people with evil intentions (so-called trolls), it is discouraging.
Captcha Example: noCAPTCHA reCAPTCHA
You already have some general knowledge about different types of CAPTCHA.
Now I want to tell you more about the newest and most popular solution: noCAPTCHA reCAPTCHA.
It was created as a result of this quite obvious realization: Bots got so advanced that it's now impossible to generate images that are easy to solve for humans but unsolvable for them.
As spammers got more sophisticated, images became harder and harder to read. But Google's research showed that it's a dead end. Today’s AI technology can solve even the most difficult distorted texts (with almost 99.8% accuracy).
So instead of making it harder for humans, they've decided to find a way to make a more advanced algorithm. Its goal is to make the checking process easy for you while still being effective in protecting against bots.
We can't say how it really works in detail because, as is understandable, it's not available to the public. What we know is that Google created sophisticated analytics technology. It somehow tries to guess if you're a human or not. If it thinks you are, you just have to check a box to prove it.
It's simple, accessible, and not annoying. If the analysis isn't enough to decide, the system asks you to solve the select-image CAPTCHA. If it's still not enough, it asks you to solve a more classic CAPTCHA, which is a lot harder than the old ones.
Now let's get back to analyzing the engine behind it. We don't know the details, but let's try to imagine how it could work.
On GitHub, you can find a great analysis of the steps reCAPTCHA takes to make it all work. Combining it with the paper "I’m not a human: Breaking the Google reCAPTCHA" (by Suphannee Sivakorn, Jason Polakis, and Angelos D. Keromytis), we know that the script gathers at least some information about:
Plug-ins
User-agent (it tests if it's real.)
Execution time, timezone
Number of click, keyboard, or touch actions in the <iframe> of the CAPTCHA
Likely cookies server-side
and it...
compares the environment with the behavior of many browser-specific functions and CSS rules
checks the rendering of canvas elements.
Also, screen resolution and mouse events don't really matter. We use different devices; we use tablets (there is almost no mouse behavior), so it seems wise. In the paper, you can also read that keeping a cookie active for +9 days allows you to pass reCAPTCHA by only clicking the checkbox.
Is the CAPTCHA a secure solution?
In order to break a CAPTCHA completely, you would have to try to manipulate your computer to think in a human manner. It's not really possible, but there are some workarounds.
Computers try to detect the text at least partly and "guess" what the result is, or use sophisticated algorithms. It's really helpful for them to have a database of already broken CAPTCHA strings. There are websites that even pay their users for solving the image CAPTCHAs. It seems that it can be really helpful for bots in the fight with CAPTCHA.
As long as people know about computers' weaknesses, they will try different approaches. They will try to tackle CAPTCHA by reducing its complexity. A clever hacker would look at the generated CAPTCHAs and analyze what makes them so hard to solve. Is there something in the background?
Let's play with contrast and get rid of middle values. If you make your image black and white, your challenge will be much simpler. If you take enough factors into account, you'll be able to build a really working algorithm.
Nobody thought that the image of the CAPTCHA would always be safe, and it was only a matter of time before it would be cracked, and it already was.
Google Image reCAPTCHA: For a long time, the Google Image reCAPTCHA system seemed like a safe choice. Unfortunately, researchers have already taught the machine to guess the correct answer. At 70.78 percent accuracy, as they recorded. It's a great result, with an average time of less than 20 seconds.
Facebook CAPTCHA: The Facebook CAPTCHA system failed even worse, with an 83.5% success rate.
A lot of images CAPTCHA systems failed against advanced algorithms.
Jennifer Tam, Jiri Simsa, Sean Hyde, and Luis von Ahn (all working for Carnegie Mellon University, Pittsburgh) wanted to figure out if it was easy to fool the sound CAPTCHA as well. They succeeded with some of them.
In the spring of 2012, there were reports that Google's audio CAPTCHA system had been broken with a 99% success rate. The engineers made a little oversight. The noise background (the main protection) didn't use high-frequency sounds. It made it easy for the hackers to isolate each word by locating the regions with higher frequencies.
And what about the newest solution: noCAPTCHA reCAPTCHA?
This technique may seem harder to crack but is not unbreakable. This year, security experts from Columbia University deployed an attack technique against Facebook and Google's noCAPTCHA reCAPTCHA.
They succeed with a 41.57 percent success rate (at about 20 seconds per challenge). It's less than 50%, but it's enough for bots to spam your website. After all, they can bombard you with hundreds of requests per minute.
How did they crack it?
They created their own sophisticated reCAPTCHA-breaking algorithm and compared it with other available CAPTCHA-breakers. Thanks to that, they've deployed a balanced solution. They've achieved such success while in offline mode. So, we can presume that a lot of noCAPTCHA reCAPTCHA power comes from analyzing user history, which is inaccessible without an internet connection.
Cons of CAPTCHA
CAPTCHA is widely used, and it can be really annoying. Let's be honest: typing some strangely shaped letters or solving any other type of challenge over and over is simply irritating.
We know why developers use it. Nevertheless, it looks like they're trying to shake off their responsibilities and make them yours. By saying that, you would be partly right. There is some truth in it, but it's really hard to find another way to do that. You can try some sophisticated algorithms, but in most cases, it's easy to fool them.
Another problem is accessibility. Even if you have great eyes, you can face problems sometimes. Identifying a valid text or image (select-image CAPTCHAS) isn't always a simple thing. And what if your vision is a little blurry or you have some kind of eye dysfunction? The audio version seems like a perfect solution, but it often has poor quality. And what if you use text-only browsers or don't have a sound card installed?
CAPTCHA also consumes your time. You could say it only takes 2.3 seconds, but now imagine that every website uses it. How many of them do you visit a day? How many actions could a site ask you to perform in order to verify your humanity?
A CAPTCHA can harm your website's usability and accessibility. Even if the new reCAPTCHA made by Google deals well with it, not every system is so good at it.
Conclusion
It seems there is no perfect solution.
With every new generation of CAPTCHA, there are new generations of bots. The more sophisticated algorithms you use to protect against them, the wiser they become. But does it mean CAPTCHA is completely useless and just annoys users?
No, the idea is still good. Even simple CAPTCHAs represent a significant barrier for most primitive bots. We shouldn't deprive you of it, but please note that CAPTCHA does not protect you and/or your users from credentials and data leakage, which can be triggered by any third-party scripts included in the page, browser extensions, or a MitB trojan.
Do you want to know more? Here are some helpful links:
CAPTCHA’s goal
Breaking CAPTCHA
CAPTCHA accessibility
Jscrambler
The leader in client-side Web security. With Jscrambler, JavaScript applications become self-defensive and capable of detecting and blocking client-side attacks like Magecart.
View All ArticlesMust read next
Defcon Skimming: A new batch of Web Skimming attacks
Jscrambler's team explores new findings about a new modus operandi in three threat groups.
December 5, 2022 | By Jscrambler | 11 min read
Protect Your Site Against Web Scraping
Known by a variety of terms like Screen Scraping, Web Harvesting, and Web Data Extracting, Web Scraping is a serious threat to companies in several sectors.
March 21, 2017 | By Shaumik Daityari | 6 min read
