The Data Processing Holy Grail? Row vs. Columnar Databases
December 5th, 2019 | By João Routar | 8 min read

Columnar databases process large amounts of data quickly. Explore how they perform when compared with row DBs like Mongo and PSQL.
Data has become the #1 resource in the world, dethroning oil as the most valuable asset. However, it may only reach its full potential if well processed. That is, extracted, stored, and analyzed dynamically and productively.
Throughout this blog post, we will cover the fundamentals for you to build efficient data processing mechanisms, emphasizing analytical solutions. Let’s look at the two main data processing systems to kick things off: Row and Columnar databases.
OLTP vs. OLAP
OLTP
OLTP, or online transaction processing, is the most traditional processing system.
It can manage transaction-oriented applications and is characterized by many short, atomic database operations, such as inserts, updates, and deletes, which are common in your day-to-day application.
Common examples include online banking and e-commerce applications.
OLAP
OLAP, or online analytical processing, manages historical or archival data. It is characterized by a relatively low volume of transactions.
OLAP systems are typically used for analytical purposes to extract insights and knowledge from bulk data merged from multiple sources.
Unlike OLTP, OLAP systems aim to have a limited number of transactions, each consisting of bulk reads and writes.
Data warehouses are the typical infrastructure to maintain these systems.
OLTP and OLAP: pros and cons
OLTP | OLAP |
Low volume of data | A high volume of data |
A high volume of transactions | Low volume of transactions |
Typically normalized data | Denormalized data |
ACID compliance | Not necessarily ACID-compliant |
Require high availability | Don’t usually require high availability |
A small explanation below: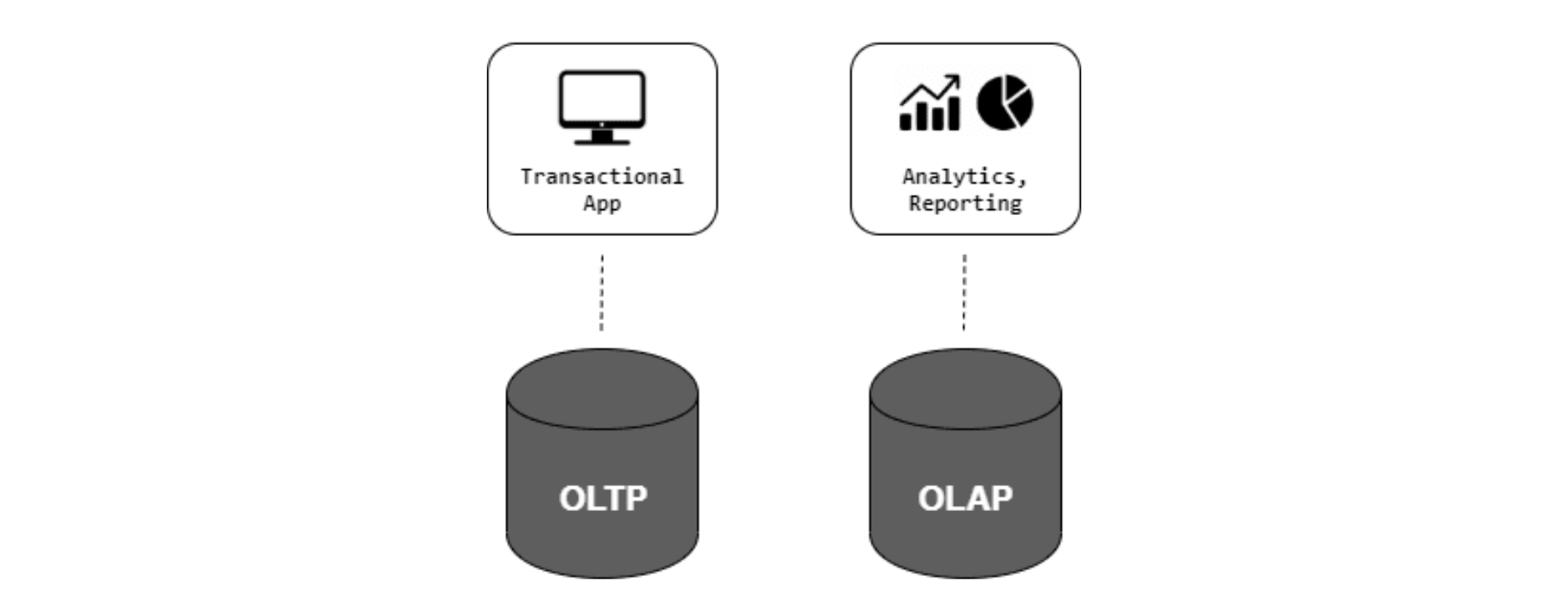
Hopefully, by vnow, you can distinguish both data processing systems easily.
OLTP and OLAP systems have been around for quite some time, but recently, with the boom of data mining and machine learning techniques, the demand for OLAP systems has increased.
Choosing a suitable technological infrastructure to host either system is crucial to ensuring your system or application delivers the best performance for your needs.
Row vs. Columnar Databases
You might have never heard of the terms row and columnar associated with databases, but you have seen them before.
Row-oriented databases are your typical transactional ones, able to handle huge transactions, whereas column-oriented databases usually have fewer transactions and a higher volume of data.
By now, you have probably already guessed which type of database is more suitable for each processing system.
Row-oriented DBs are commonly used in OLTP systems, whereas columnar ones are more suitable for OLAP. Some examples include:
Row-oriented | Columnar |
MySQL | Amazon Redshift |
PostgreSQL | MariaDB |
Oracle | ClickHouse |
... | ... |
What makes row and columnar databases different internally?
The difference between both data stores is how they are physically stored on disk.
HDDs are organized in blocks and rely on expensive head-seek operations; thus, sequential reads and writes tend to be much faster than random accesses.
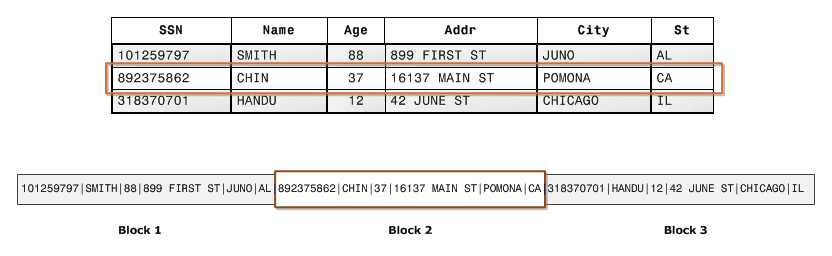
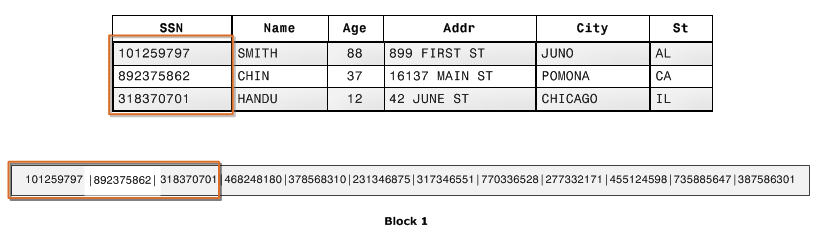
Row-oriented databases store the whole row in the same block, if possible. Columnar databases store columns in subsequent blocks.
But what does this mean in practice?
Amazon Redshift provides a simple and concise explanation highlighting the differences between both databases.
The figure below consists of row-wise database storage, where each row is stored in a sequential disk block.
Picking the ideal block size is essential to achieving optimal performance since having a block size that’s too small or too big results in inefficient use of disk space.
The figure below portrays columnar database storage, where each disk block stores the values of a single column for multiple rows.
In this example, columnar storage requires one-third of the I/O disk operations to extract the columns’ values, compared to a row-wise database.
Performance Example
Let’s look at a simple example to understand the differences between both databases.
Consider a database storing 100GB of data, with 100 million rows and 100 columns (1GB per column).
For simplification purposes, consider that the database administrator is a rookie and hasn’t implemented any indexes, partitioning, or other optimization processes on the database. With this in mind, for the analytical query:
What is the average age of males?
We would have these possibilities:
Row-wise DB: Has to read all the data in the database (100) - 100GB to read.
Columnar DB: Has to read only the columns age and gender - 2GB to read.
This is an extreme example. Hardly any database will completely lack indexes or other optimization processes, but the goal is to give you an overview of columnar databases’ true potential for analytical purposes.
Row and Columnar Databases Wrap-up
Now that you have an overview of row-oriented and columnar databases, as well as the main differences between them, highlighting their advantages (green) and disadvantages (red) shouldn’t be too hard:
Row-oriented DB: for OLTP | Columnar DB: for OLAP |
Performs fast multiple read, write, update, and delete operations | Performs slowly if required to perform multiple read, write, update, and delete operations |
Bulk operations (read and write) aren’t fast | Performs fast bulk operations (mostly read and write) |
ACID compliance | No ACID compliance |
Typically inefficient data compression | Improved data compression: Columns are individually compressed, and each one is of the same type |
High storage size (indexes, etc.) | Low storage size |
Typically require multiple indexes, depending on queries | Relies on a single index per column (self-indexing) |
It is easy to add a single row (1 insert operation) | It is hard to add a single row (multi-column insert operation) |
It is hard to add a single column (multi-row insert operation) | It is easy to add a single column (1 insert operation) |
Benchmarks
Everyone loves theoretical concepts (well, at least let’s suppose so), but why not put them into practice?
With this in mind, we set up an experiment to compare their performance in a real-world scenario. We used different technologies to compare their performance on OLTP and OLAP systems. The technologies selected were:
OLTP
MongoDB is a NoSQL database widely used in several applications. Excels at delivering fast and dynamic transactions, made possible by its schema-free, document-oriented mechanism.
PostgreSQL is a free and open-source database that is widely dynamic and extensible. Uses range from small applications to data warehouses.
Citus is a “worry-free Postgre built to scale out”. It is a PostgreSQL extension that distributes data and queries across several nodes.
OLAP
Cstore_fdw is an open-source Postgres extension developed by Citus Data. It transforms the original row-oriented Postgres database into a columnar database.
ClickHouse is a recent, open-source columnar database developed by Yandex. It claims to be capable of delivering real-time analytical data reports using a SQL-like syntax.
Queries Performance
To conduct the benchmark, we used a database with approximately 135 million records of web event logs distributed across four different tables.
All the technologies were used on-premise, on a local machine with an i5-9600k processor clocked at 3.70 GHz coupled with 32GB of RAM.
We made a set of queries typically considered analytical (i.e., focus on columns rather than rows). To make the process as homogeneous as possible, for each query we ran, we flushed the respective storage engine’s cache and restarted the machine each time we switched technology.
For the row-wise databases, we built the most efficient indexes for the queries we created. We built no indexes for the columnar storage other than the ones created by default upon populating these databases. The results are displayed in the table below.
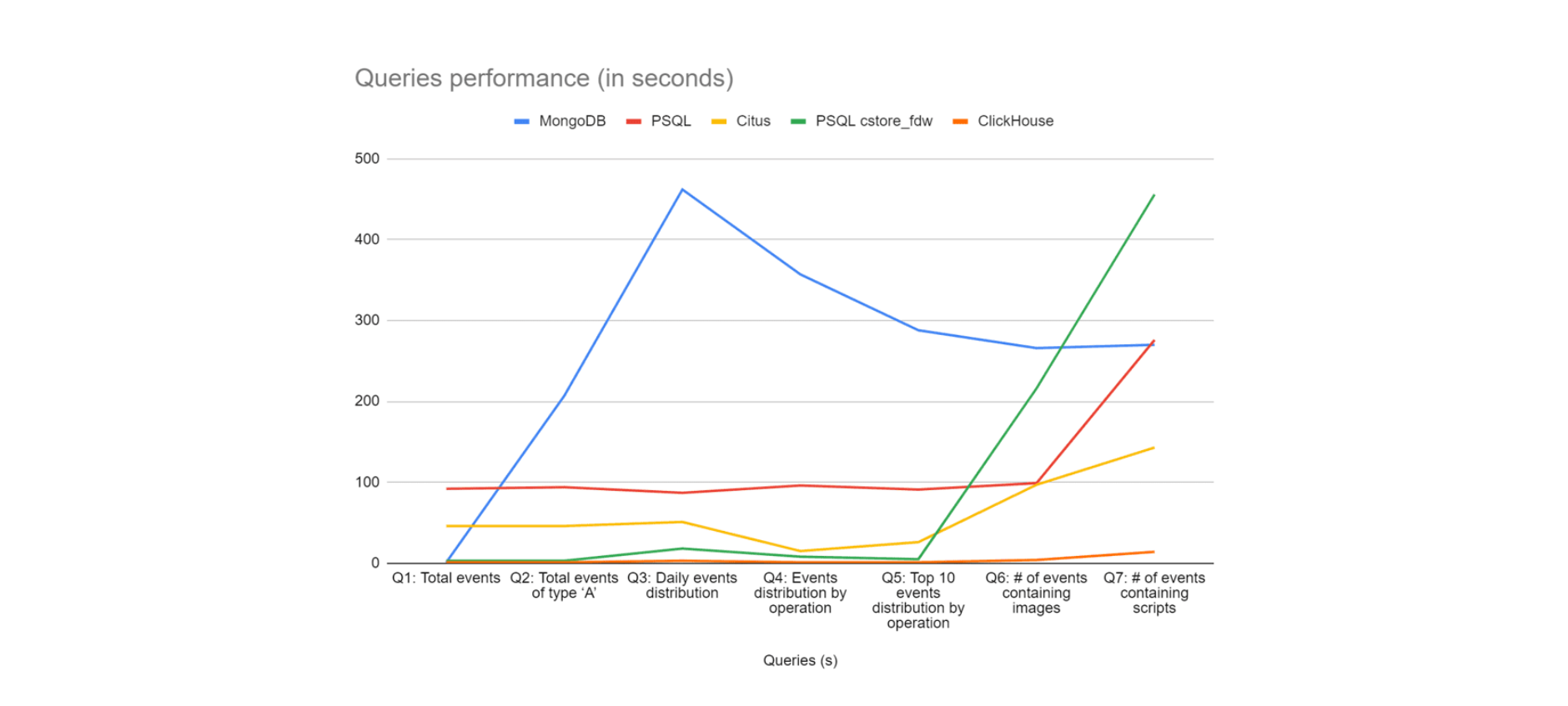
Queries (s) | Mongo DB | PSQL | Citus | PSQL cstore_fdw | Click House |
Q1: Total events | 1 | 92 | 46 | 3 | < 1 |
Q2: Total events of type ‘A’ | 207 | 94 | 46 | 3 | < 1 |
Q3: Daily events distribution | 462 | 87 | 51 | 18 | 3 |
Q4: Events distribution by operation | 357 | 96 | 15 | 8 | < 1 |
Q5: Top 10 events distribution by operation | 288 | 91 | 26 | 5 | < 1 |
Q6: # of events containing images | 266 | 99 | 97 | 216 | 4 |
Q7: # of events containing scripts | 270 | 276 | 143 | 456 | 14 |
By looking at the data above, it is no surprise that columnar databases (i.e., PostgreSQL cstore_fdw and ClickHouse) have considerably shorter running times when compared to the other technologies. However, cstore_fdw is under-optimized for queries that require joining tables (e.g., left join) and performing a text search, as denoted by the running times for queries Q6 and Q7.
ClickHouse, on the other hand, outperforms every single technology by far, especially when it comes to cstore_fdw’s caveats: joins combined with text search.
While ClickHouse doesn’t inherently support joining tables. This issue can be bypassed by using subqueries.
The image below displays a comparative view of all the technologies and their performance on the analytical queries (lower is better).
Storage Size
As you might recall from our first comparison table, columnar storage has improved compression mechanisms over row-wise databases. This happens because each column, compressed as a single file, has a unique data type.
Besides, these databases don’t have indexes besides the one created by default for the (primary) key.
Such features allow for highly efficient storage space, as shown on the graph below, with ClickHouse taking 10GB of space, followed by the raw data itself with 76GB occupied, and, finally, PostgreSQL, with 78GB of taken storage space. This is a 780% increase over ClickHouse.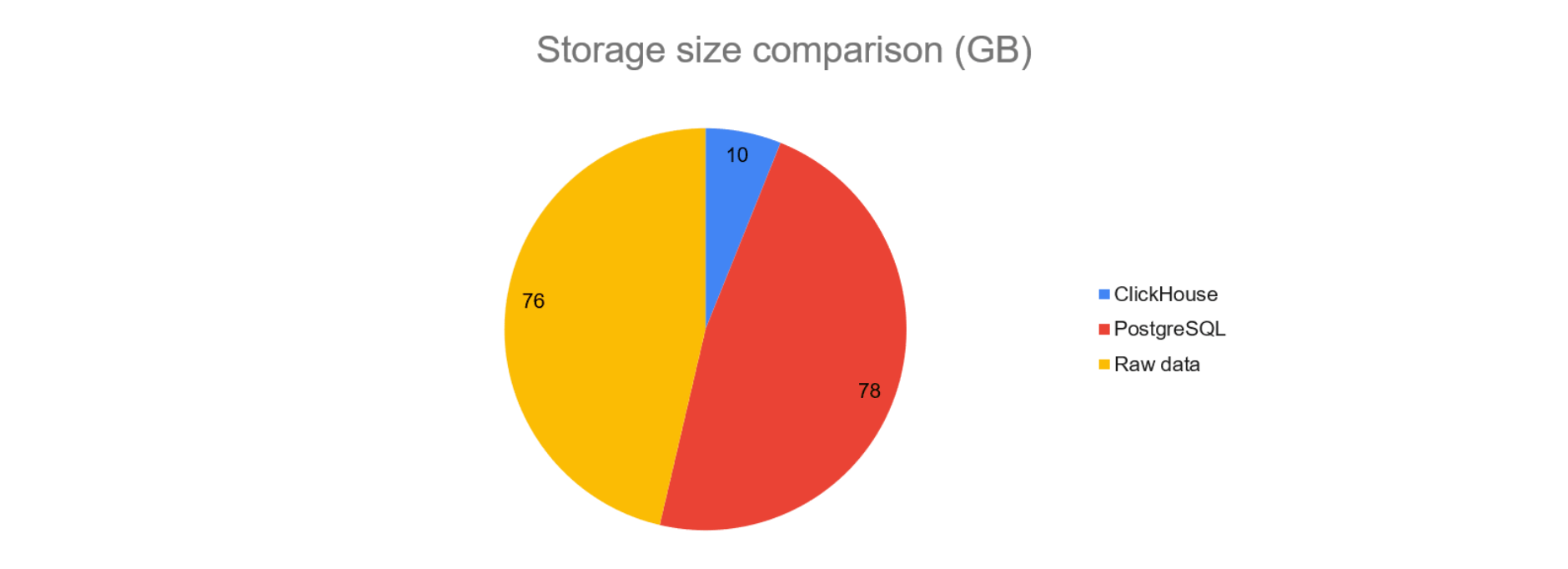 Note that for PostgreSQL (and other row-wise databases), besides the space data occupies, indexes also contribute to the substantial increase in storage.
Note that for PostgreSQL (and other row-wise databases), besides the space data occupies, indexes also contribute to the substantial increase in storage.
Final Remarks
Columnar databases are rather incredible at what they do: processing massive amounts of data in seconds or even less. There are many examples (Redshift, BigQuery, Snowflake, MonetDB, Greenplum, MemSQL, ClickHouse) with optimal performance for your analytical needs.
However, their underlying architecture introduces a considerable caveat: data ingestion. They offer poor performance for mixed workloads that require real-time high throughput. In other words, they can’t match a transactional database’s real-time data ingestion performance which allows the insertion of data into the system quite fast.
Combining fast ingestion and querying is the holy grail of data processing systems.
Achieving an optimal mixed workload is probably not possible at this point since there is no single do-it-all technology that excels at both. Having a database for each purpose is the typical way to go. However, it limits the performance of the whole system.
Data processing is a complex but interesting technical design area. We firmly believe that scalable real-time high-throughput analytical databases are possible, but they don’t exist.
Yet.
Jscrambler
The leader in client-side Web security. With Jscrambler, JavaScript applications become self-defensive and capable of detecting and blocking client-side attacks like Magecart.
View All ArticlesMust read next
Tracking Pixels Security: the Debate Marketers Face
Tracking pixel security faces a vocal battle between digital marketers, data protection advocates, cybersecurity experts, and users. How can enterprises protect online privacy without compromising...
June 4, 2024 | By Joyrene Thomas | 10 min read
Build Database Relationships with Node.js and MongoDB
Let's dive deeper into MongoDB and understand how relationships work between MongoDB collections in a Node.js server application.
September 10, 2019 | By Connor Lech | 8 min read
