
Table of contents
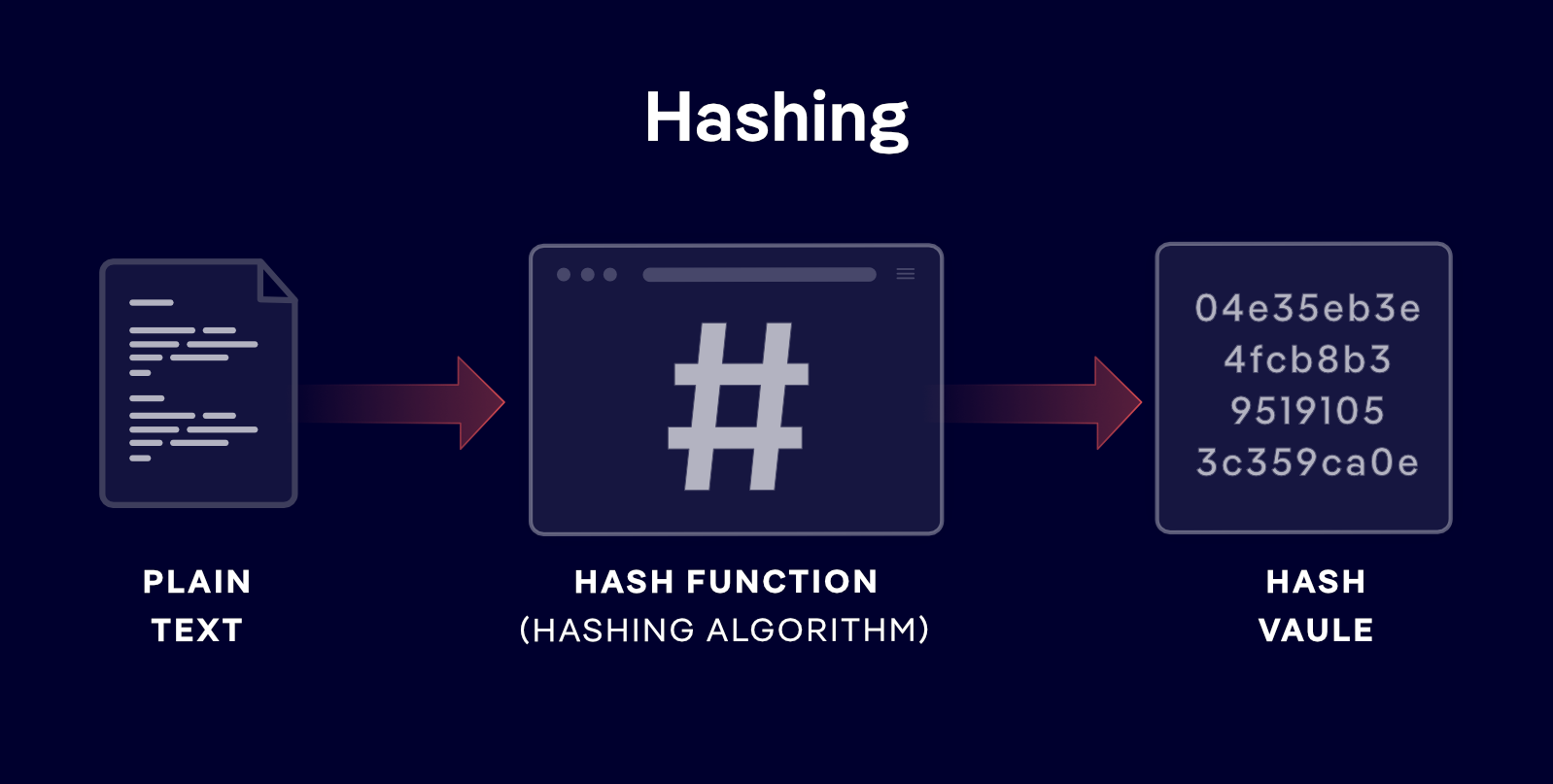
Hashing is the process of taking any piece of data- a password, a file, a message- and converting it into a short, fixed-length string of characters called a hash, digest, or fingerprint. A Hashing Algorithm (a mathematical function) performs this conversion by processing the input and producing the output. That output uniquely represents the original data without containing any recoverable trace of it.
The most important thing to understand about hashing is that it is a one-way process. Unlike encryption, there is no reverse operation. Once data has been hashed, the original input cannot be reconstructed from the output, only verified against it. That irreversibility is the foundation of how hashing protects data in modern systems.
What Is a Hash Function?
The mathematical engine that does the hash is called a hash function. It is a particular type of function that takes an argument of arbitrary size and returns a fixed-size, predetermined one, mapping an infinite input space to a finite output space in a consistent, deterministic manner.
A cryptographic hash function differs from a simple calculation because it has certain properties that must always be true: If the same input is given to the function, the output will be the same; small changes in the input will result in an output completely different from what was originally obtained; and it should be difficult to find any pair of inputs that will result in the same output. These guarantees make hash functions reliable in security-sensitive applications.
What Is a Hashing Algorithm?
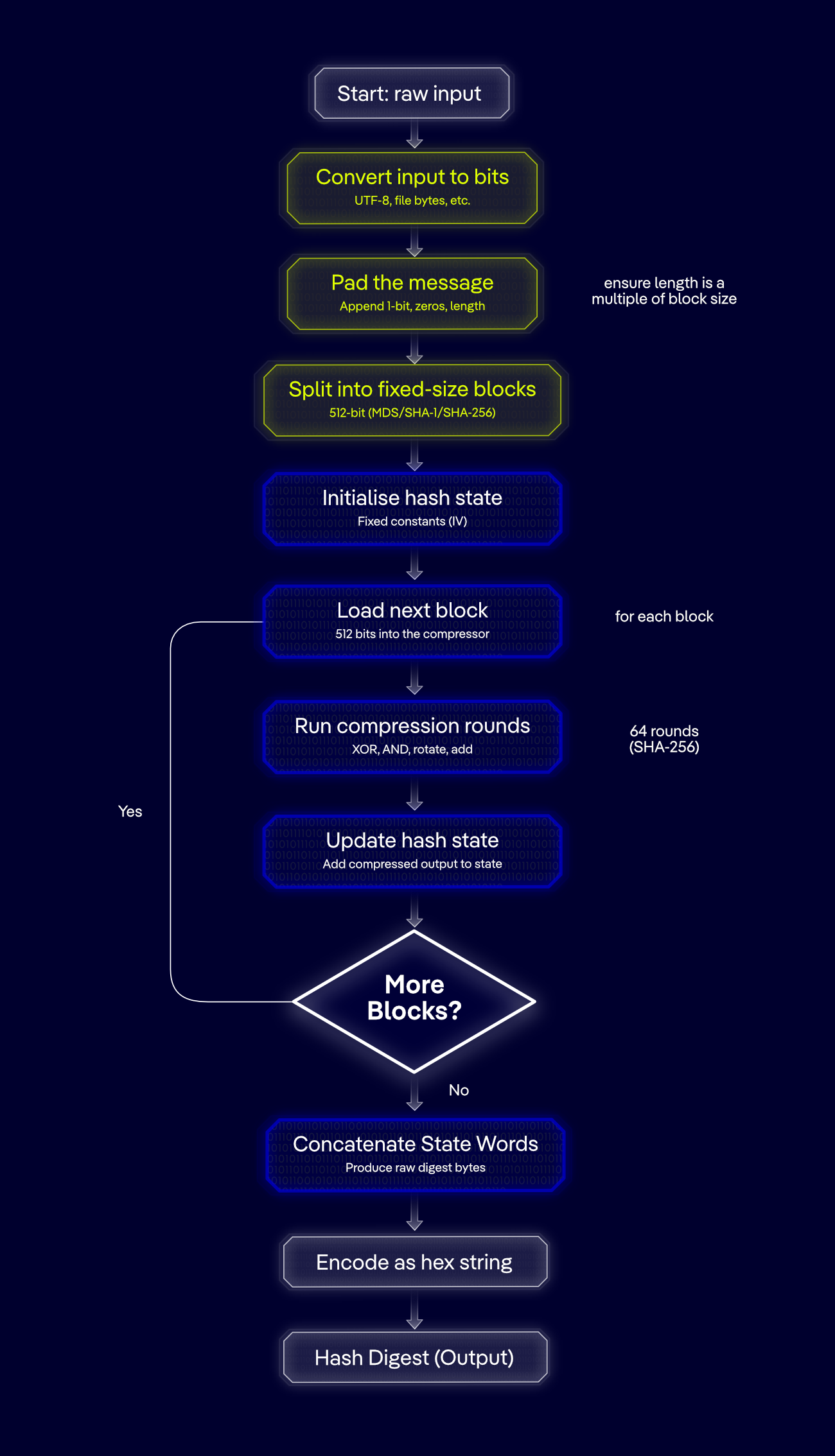
A hash function is the idea, and a hashing algorithm is the actual plan or procedure. It is an exact, step-by-step sequence of instructions that a computer follows to convert input into a hash, specifying how the input is padded, divided into blocks, processed mathematically, and compressed into the final digest. Each of these hashing algorithms, including SHA-256, MD5, bcrypt, and Argon2, defines a specific method for implementing the hash function.
The distinction matters in practice. When a cryptographer discusses a "hash function," they speak about abstract mathematical properties. When an engineer asks "which hashing algorithm should I use," they are asking about the specific implementation, like how fast it is, how resistant it is to attacks, and what it is optimized for. A hashing algorithm is the realization of a mathematical idea in executable form.
Hashing Algorithms Process Explained
The process of hashing might look like magic from the outside, but it follows a strict, deterministic sequence of events.
Step-by-Step Hashing Process
Input data enters the algorithm: The user, system, or application provides the initial data in its raw format (text, binary data from a file, etc.).
Mathematical transformation occurs: The hashing algorithm breaks the data into fixed-size blocks. It then runs these blocks through a series of logical operations, bitwise shifts, and modular arithmetic. Each block's outcome affects the processing of the next.
Fixed-length hash is generated: After the final computational round, the algorithm outputs a completely new string of characters. Regardless of the input's original size, this output string maintains a fixed length determined by the specific algorithm used.
Why Hashes are Considered One-Way Functions
Secure hashes are specifically designed to be computationally impossible to reverse. When data is hashed, information is intentionally lost through operations such as modulo division. Because multiple inputs could technically produce the intermediate steps, there is no way for a computer to work backward from the final hash to determine the exact original input.
Common Types of Hashing Algorithms
MD5
MD5 was designed by Ronald Rivest in 1991 and produces a 128-bit digest. For a decade, it was the most widely deployed hash function in the world, used in digital signatures, certificate signing, and password storage. It is now cryptographically broken. Practical collision attacks were demonstrated in 2004, and by 2008, researchers had used MD5 collisions to forge a rogue SSL certificate trusted by every major browser.
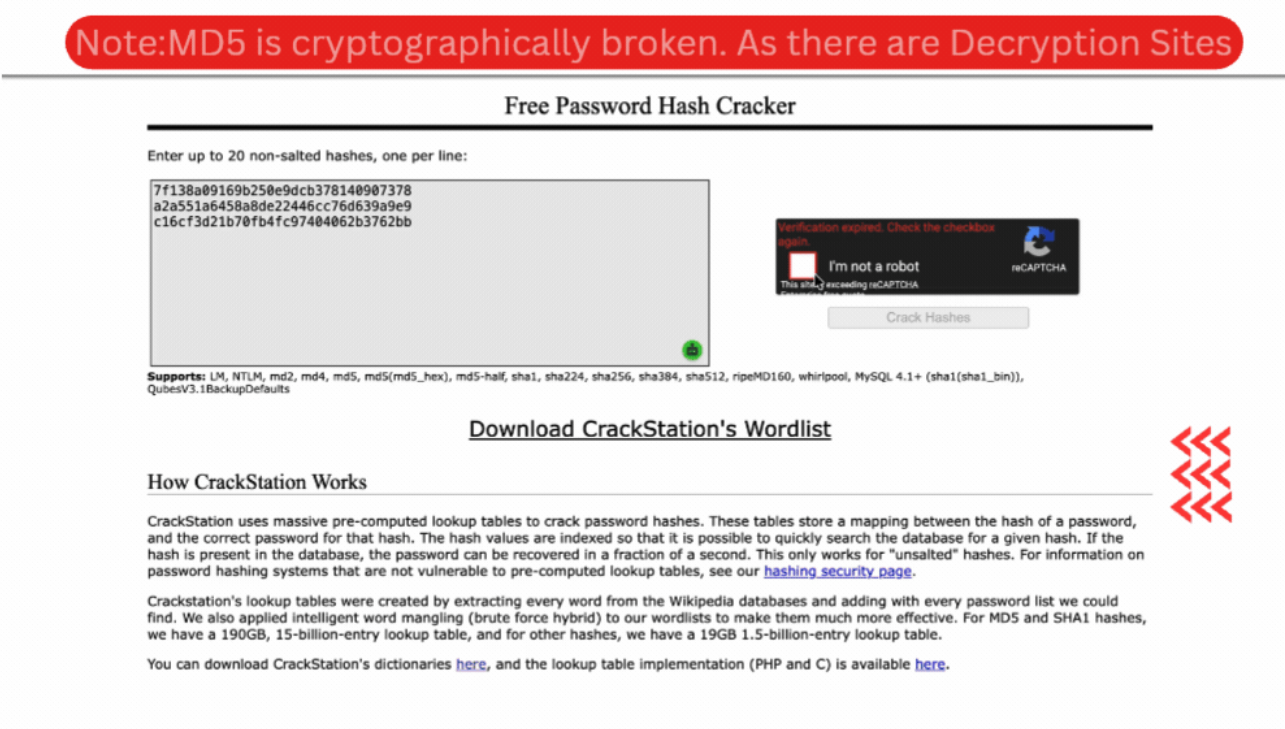
Today, MD5 is appropriate only in non-security contexts where collisions carry no consequence, such as partitioning data across distributed caches or generating non-critical file identifiers. Its fatal flaw for password storage is raw speed. Modern GPUs can compute over 100 billion MD5 hashes per second, meaning a stolen database of MD5-hashed passwords can be brute-forced in hours. Using MD5 for any security-sensitive purpose in 2026 is not a legacy risk; it is an active vulnerability.
SHA Family
The Secure Hash Algorithm family was developed by the NSA and standardized by NIST, representing the evolution of cryptographic hashing from 1995 through today.
SHA-1 produces a 160-bit digest and dominated SSL/TLS certificate signing for over a decade. Theoretical weaknesses emerged in 2005. The full practical break came in 2017, when Google's SHA-1 Shattered research team produced two different PDF files with identical SHA-1 hashes. Every major browser and certificate authority discontinued SHA-1 support. It is fully deprecated.
SHA-2 is a family of variants, including SHA-256, SHA-512, and others, that share the same internal Merkle-Damgård structure. SHA-256 is by far the most deployed, forming the backbone of TLS, Bitcoin, code signing, and DNSSEC. No practical attack against SHA-256 has been demonstrated, and it remains the standard recommendation for general-purpose cryptographic hashing.
SHA-3 was standardized in 2015 after a five-year public competition, selecting the Keccak algorithm, which uses a fundamentally different sponge construction rather than the Merkle-Damgård construction. It is not a replacement for SHA-2 but a structurally independent alternative insurance against any future weakness discovered in SHA-2's construction. Its architecture eliminates length extension vulnerabilities and supports extendable output variants (SHAKE128, SHAKE256) used in post-quantum cryptographic constructions.
Bcrypt
Bcrypt was designed in 1999 specifically for password hashing and solved the core problem that general-purpose hash functions cannot: it is deliberately slow. Its defining feature is a tunable cost factor that controls how many iterations of the core function are performed, allowing administrators to increase computational cost as hardware improves without changing the algorithm.
Bcrypt incorporates a 128-bit salt automatically and is built around a modified Blowfish cipher key schedule. At cost factor 12 on modern hardware, Bcrypt computes roughly 250–500 hashes per second, compared to billions per second with SHA-256. An attacker who steals a database of bcrypt-hashed passwords faces a brute-force task measured in years rather than hours. Bcrypt is mature, battle-tested, and remains a solid choice for systems already using it.
Scrypt
Scrypt, published by Colin Percival in 2009, introduced memory hardness to password hashing. Where Bcrypt requires many sequential computations but relatively little memory, Scrypt requires both substantial computation and a large, configurable block of RAM. This matters because GPU and ASIC hardware, the tools attackers use for large-scale cracking, can parallelize computation cheaply but cannot scale memory bandwidth at the same rate.
Scrypt's memory requirements mean that running many instances simultaneously requires proportionally more RAM, drastically reducing the parallelism advantage that specialized hardware provides. Scrypt is parameterized by CPU/memory cost, block size, and parallelism factor. It is widely used in cryptocurrency mining and remains a strong choice for password hashing in environments with sufficient memory resources to configure it properly.
Argon2
Argon2 won the Password Hashing Competition in 2015 and is the current best-practice recommendation for all new systems. It builds on the lessons of both Bcrypt and Scrypt while adding resistance to GPU, FPGA, and side-channel attacks. It comes in three variants: Argon2d (maximizes GPU resistance), Argon2i (resists side-channel attacks), and Argon2id (combines both and is the recommended default for most applications).
Argon2 is parameterized by time cost, memory cost, and parallelism, giving administrators precise control over resource requirements. A typical secure configuration requires 64MB of RAM and 3 iterations, producing a hash in 250–500 milliseconds on a modern server imperceptible during login but deeply punishing for any attacker running a cracking campaign. As of 2026, no practical attack against well-configured Argon2id exists.
Hashing vs Encryption vs Encoding
These three operations are entirely different in purpose, reversibility, and appropriate use. Confusing hashing and encryption, in particular, is one of the most common and consequential mistakes in application security.
Feature | Hashing | Encryption | Encoding |
Reversible? | No | Yes (with key) | Yes (always) |
Purpose | Integrity & verification | Confidentiality | Data formatting |
Uses a key? | No | Yes | No |
Output length | Fixed | Variable | Variable |
Example | SHA-256, bcrypt | AES, RSA | Base64, UTF-8 |
Common Misconceptions Explained
Firstly, hashing is not encryption; hashing is irreversible, while encryption is meant to be reversible. Secondly, Base64 does not provide security; it is merely a formatting tool, equivalent to storing passwords in plaintext. Finally, not all hashes are suitable for passwords; take a look at the SHA-256 algorithm: while good for file integrity, it is poor for password security, regardless of how fast it is. A dedicated password hashing algorithm should always take precedence over speed when it comes to password security.
Salting and Peppering
What Is a Salt?
A Salt is a random value, unique to each user, used when hashing a password. If not salted, two users with the same password generate the same stored hash; if one of their passwords is compromised, all users sharing that password are compromised. A unique salt means that no two passwords are the same; hence, the hash value of each password is different, which makes it necessary for an attacker to crack each password separately.
It doesn't have to be hidden; it's usually kept in the database with the hash. The typical minimum is 16 bytes of random data generated per password. New hash functions such as bcrypt and Argon2 include the salt in their output, so it does not need to be handled by the developer.
What Is a Pepper?
A pepper is a hidden value (outside of the salt) added to the password before or after hashing. The pepper is not kept in the database at all, unlike the salt. It's stored in the application configuration, in environment variables, or in a hardware security module. If the attacker gains access to the full database, they won't be able to guess any password without compromising the pepper, since the attacker's hash will never match the hashes stored in the database.
Peppering is a valuable addition to salting. These two are used together: the salt provides a unique value for each user, and the pepper ensures that if someone steals the database, it won't be enough to crack it. A typical implementation uses HMAC with the pepper argument before passing to the password hash function.
Hashing in Cybersecurity
A hashing function is the final verification function in cybersecurity. If an OS is asking for an update, it will download the update file and the vendor-provided hash. The downloaded file is processed locally, and the resulting hash is compared with the file's hash. If they do match, the update is not bogus. Even a single line of malicious code injected in transit would cause the hashes to differ, and the system would abort the installation.
Hashing in Cryptography
Advanced cryptography relies on hashing to create Digital Signatures and Message Authentication Codes (MACs) by hashing a message and then encrypting that hash with a private key, a sender can prove both that they authored the message (authentication) and that it hasn't been altered (integrity).
Hashing in Data Structures
Outside of security, hashing is vital for computer science performance. Hash Tables (or Hash Maps) use lightweight hashing algorithms to organize data for incredibly fast retrieval. Instead of searching a database row by row, an application can hash a search term to find the exact memory address where the relevant data is stored, making data retrieval nearly instantaneous.
Collision
A collision occurs when two different inputs produce the same hash value. In theory, collisions are unavoidable because there are infinitely many possible inputs but a finite number of possible hash outputs. The goal of a secure hashing algorithm is not to eliminate collisions but to make finding them computationally impractical.
Collision resistance is one of the most important properties of modern cryptographic hash functions because successful collision attacks can compromise data integrity and digital signature systems. This is one of the primary reasons the older algorithms, such as MD5 and SHA-1, are no longer recommended: successful collision attacks against them have occurred.
Hashing algorithms are crucial tools for achieving a balance between data performance and security. In simple terms, hashing makes it easy to establish digital trust, whether it's a basic data look-up or a complex cyberattack that's capable of breaking billions of user credentials. Knowing the various algorithms used by high-speed file verifiers such as SHA-256 and memory-hard password protectors such as Argon2, developers and security experts can create resilient systems that can ensure that data remains exactly as it was meant to be.


