Hashing Algorithms
August 12th, 2020 | By Jscrambler | 8 min read

Hashing algorithms are mathematical functions that make data unreadable and unscrambled by anyone else. What is the strongest hash algorithm? Why are hashing algorithms useful?
Imagine you have an important file to send, and you want to ensure it will get to the addressee without any changes and in one piece. You could use some trivial methods, like sending it multiple times, contacting the addressee and verifying the file, and so on. But there’s a much better approach: using a hashing algorithm.
What is a hash function?
Hashing algorithms are functions that generate a fixed-length result (the hash, or hash value) from a given input. The hash value is a summary of the original data.
For instance, think of a paper document that you keep crumpling to the point where you aren’t even able to read its content anymore. It’s almost (in theory) impossible to restore the original input without knowing what the starting data was.
Let’s look at a hashing algorithm example with a simple hash function:
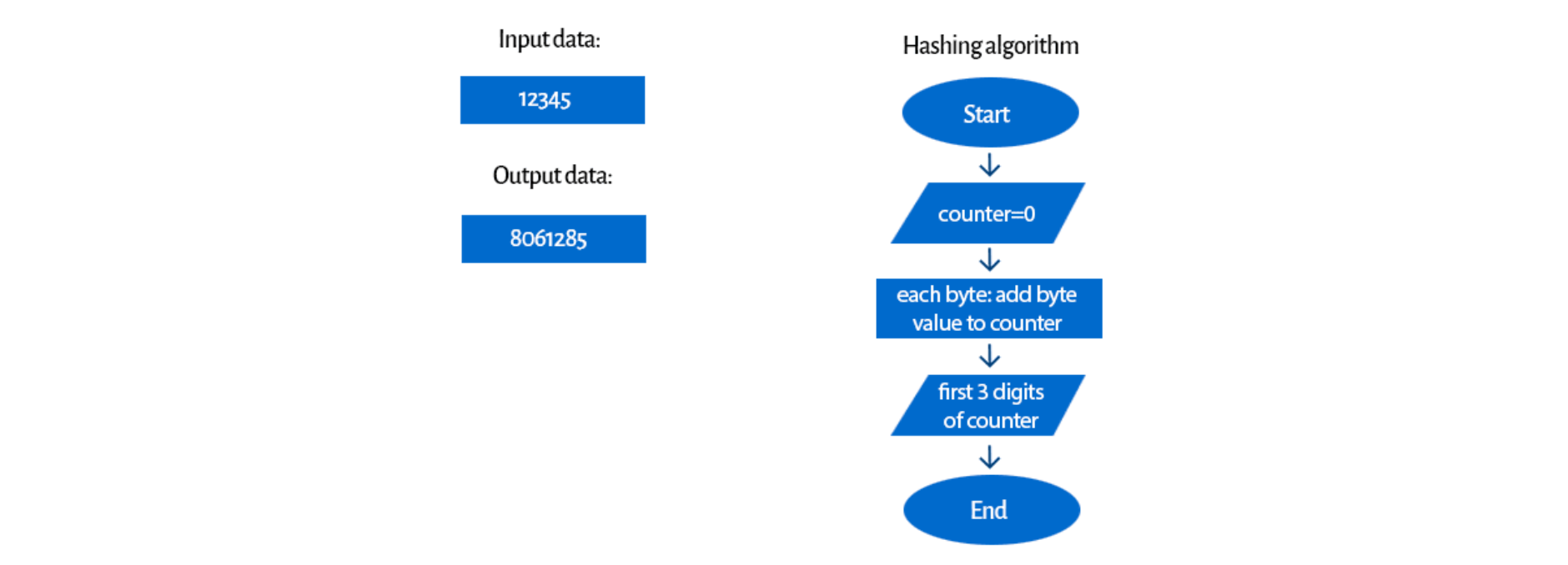
We could discuss if it’s a secure algorithm (spoiler alert: it isn’t). Of course, every input number is individual (we’ll talk more about this in further sections), but it’s easy to guess how it works. This is a very simple example, but it gives us an idea of what a hashing algorithm can look like.
To learn more about hashes, check out this very thorough Wikipedia page.
How does a hashing algorithm work?
A hashing algorithm is a cryptographic hash function. It is a mathematical algorithm that maps data of arbitrary size to a hash of a fixed size.
A hash function algorithm is designed to be a one-way function, that is impossible to invert. However, in recent years, several hashing algorithms have been compromised.
What is the MD5 hash algorithm?
MD5, for example, is a widely known hash function designed to be a cryptographic hash function that is now so easy to reverse that we could only use it for verifying data against unintentional corruption.
What should the ideal cryptographic hash function be like?
It should be fast to compute the hash value for any kind of data;
It should be impossible to regenerate a message from its hash value (brute force attack is the only option);
It should be impossible to find two messages with the same hash (a collision);
Every change to a message, even the smallest one, should change the hash value. It should be completely different. It’s called the avalanche effect.
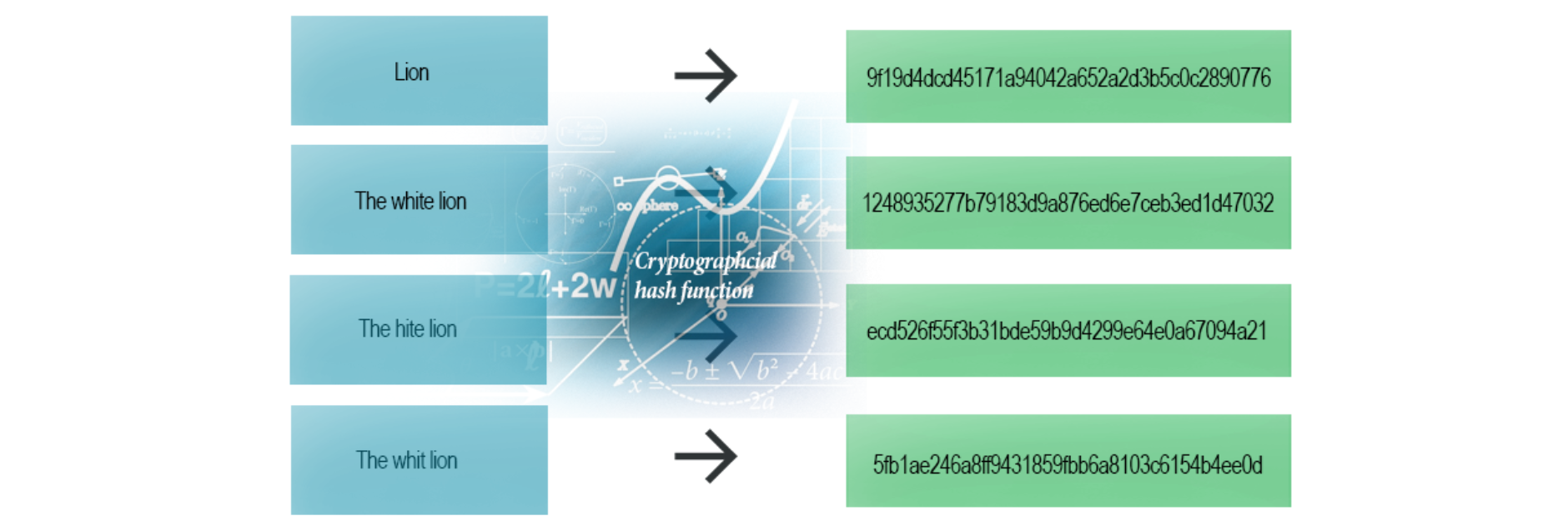 Even the smallest change (one letter) makes the whole hash different (SHA-1 example)
Even the smallest change (one letter) makes the whole hash different (SHA-1 example)
How are cryptographic hash functions used?
Cryptographic hash functions are widely used in IT.
We can use them for digital signatures, message authentication codes (MACs), and other forms of authentication. We can also use them for indexing data in hash tables, fingerprinting, identifying files, detecting duplicates, or as checksums (we can detect if a sent file didn’t suffer accidental or intentional data corruption).
We can also use them for password storage. If you have a website, you most likely do not need to store the passwords of your users. You just need to check whether the user password and the password of any given attempt match, so hashes should work fine and give some additional protection to your users.
If you want to know more about hashing passwords and their security, see our previous article about how to store passwords safely.
After this section, we’ll show you an example of the last feature.
How do MACs work?
Digital signature
Hash tables
Hashing Algorithm Example
So, how does it work?
Let’s get back to our hashing algorithm example. We’re sending a file to our friend. It’s a really important file, and we want to ensure it has been received in one piece. That’s when our hashing algorithm comes in. But first, let’s think about how our file transfer would look without it: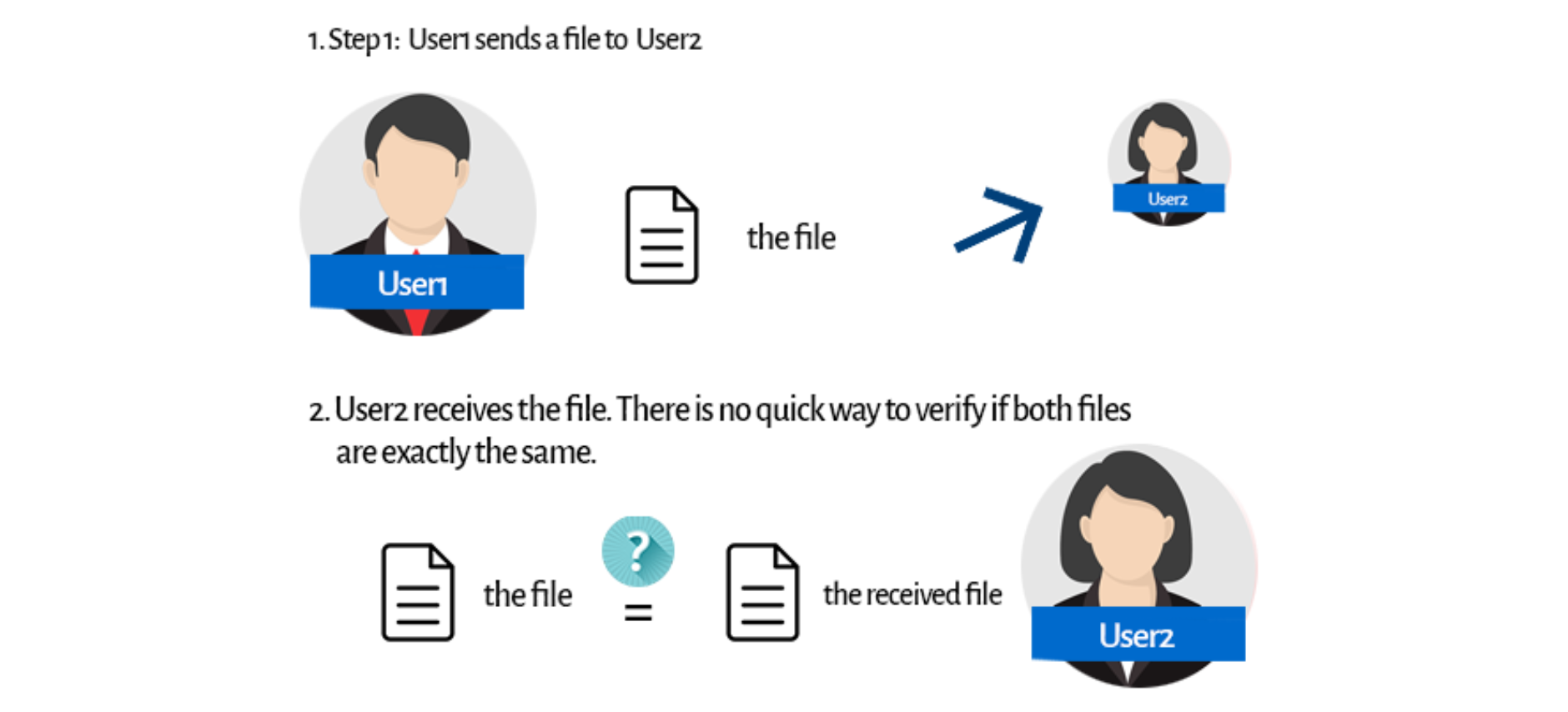 We can figure out some trivial ideas. You could, for instance, call User2, and you could check the file content together. But then, what’s the point of sending a file? Checksums are our godsend here.
We can figure out some trivial ideas. You could, for instance, call User2, and you could check the file content together. But then, what’s the point of sending a file? Checksums are our godsend here.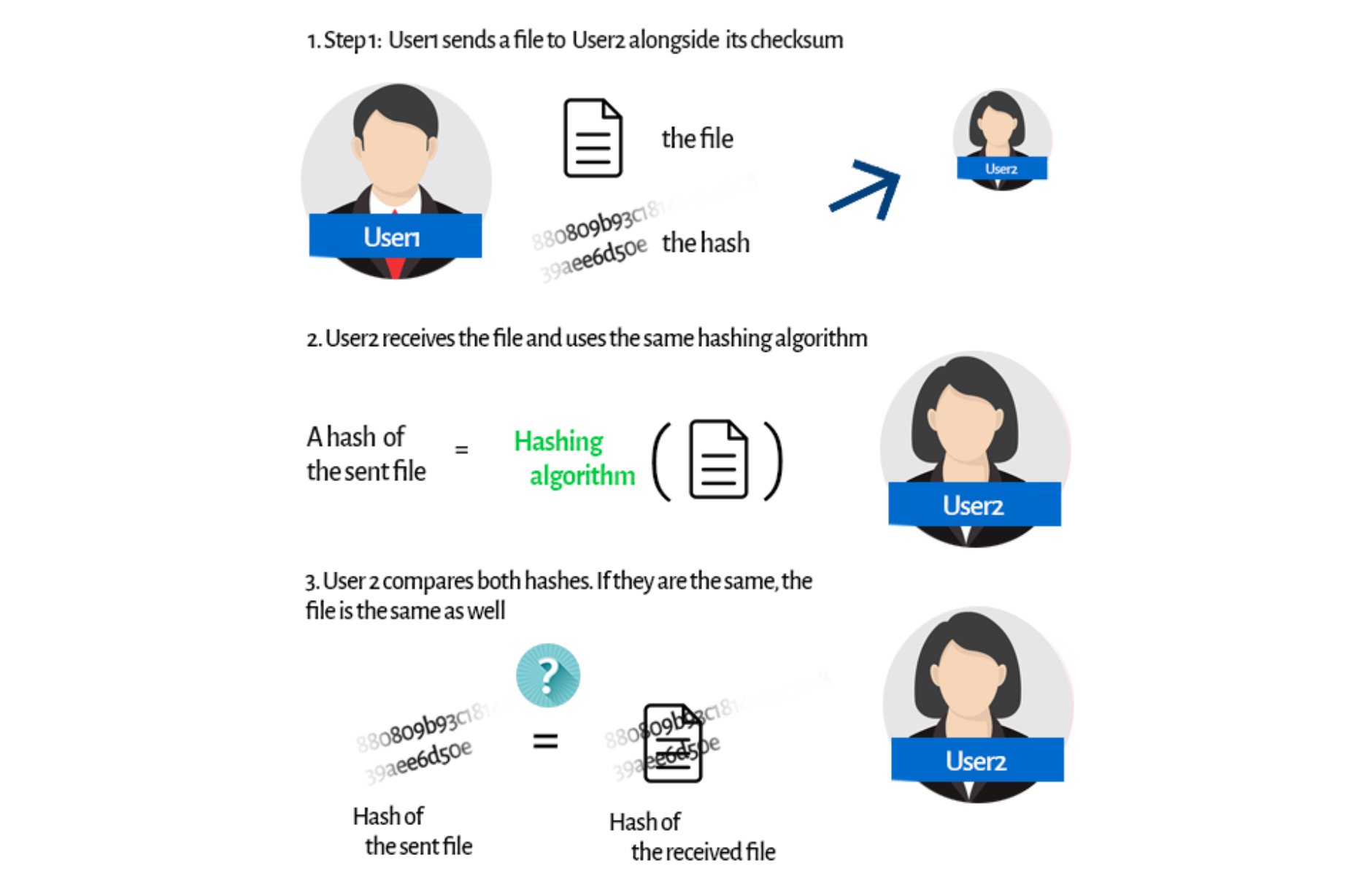 Before sending a file, User1 uses a hashing algorithm to generate a checksum for the file. Then he or she sends it along with the file itself. User2 receives both the file and the checksum. Now he/she can use the same hashing algorithm on the received file. What’s the point?
Before sending a file, User1 uses a hashing algorithm to generate a checksum for the file. Then he or she sends it along with the file itself. User2 receives both the file and the checksum. Now he/she can use the same hashing algorithm on the received file. What’s the point?
We already know that a hash is individual (so there can’t be any other file with the same hash) and has to always be the same for an individual file.
No matter how many times you use the hash algorithm, it will always give you the same result. So now, User2 can compare both hashes. If they’re the same, it means they're generated from the same file. There is no way that any other file has the same hash, and there is no chance for a hash to be different for the same file.
This way, User2 can verify if the file isn’t in any way corrupted. Easy? Certainly.
A lot of downloading services use checksums to validate the integrity of their files. Thanks to that, you can find out if your downloaded file isn’t corrupted.
What are the most popular hashing algorithms?
MD5
Before we go any further, MD5 is completely broken!
If you ever learned any programming language, and it was some time ago, you surely know this algorithm. It’s one of the most widely known.
This hash algorithm used to be widely used and is still one of the most widely known hashing algorithms. But despite initially being designed to be used as a cryptographic algorithm function, it is no longer considered safe to use for cryptographic purposes, as it is compromised. In particular, it is possible to quickly generate collisions on ordinary computers.
When MD5 is used to hash passwords directly, there is an even easier way to break them: Google. By typing the hash in the search box, there's a good chance you'll receive its before state within milliseconds!
Now let’s look at this example: You could think you are secure if your passwords are stored as MD5 hashes, but if somebody gets access to your database, he/she can just type the hash into Google and get its real value!
You could think you are secure if your passwords are stored as MD5 hashes, but if somebody gets access to your database, he/she can just type the hash into Google and get its real value!
The CMU Software Engineering Institute considers MD5 essentially “cryptographically broken and unsuitable for further use”. It was accepted for many years, but it’s now mainly used for verifying data against unintentional corruption.
SHA-family
The Secure Hash Algorithm is a cryptographic hash function designed by the United States NSA.
SHA-0 (published in 1993) was compromised many years ago. SHA-1 (1995) produces a 160-bit (20-byte) hash value. It’s typically rendered as a 40-digit hexadecimal number. It was compromised in 2005 as theoretical collisions were discovered, but its real “death” occurred in 2010, when many organizations started to recommend its replacement.
The big three — Microsoft, Google, and Mozilla — stopped accepting SHA-1 SSL certificates in 2017 on their browsers after multiple successful attacks. SHA-1 was built on principles similar to those used in the design of MD4 and MD5. It has a more conservative approach, though.
Safer, for now, is SHA-2. SHA-2 includes several important changes. Its family has six hash functions with digests: SHA-224, SHA-256 or 512 bits: SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224, SHA-512/256.
There are numerous reasons why you should move to SHA-2.
As a bottom line, SHA-2 is a lot more complicated but is still considered safe. However, SHA-2 shares the same structure and mathematical operations as its predecessor (SHA-1)—so it's likely that it will be compromised shortly. As such, a new option for the future is SHA-3.
SHA-3 (Secure Hash Algorithm 3) was designed by Guido Bertoni, Joan Daemen, Michaël Peeters, and Gilles Van Assche. Their algorithm, Keccak won the NIST contest in 2009 and has been adopted as an official SHA algorithm. It was released by NIST on August 5, 2015. One of SHA-3's requirements was to be resilient to potential attacks that could compromise SHA-2.
Keccak is significantly faster than SHA-2 (from 25% to 80%, depending on implementation). It uses sponge construction. The data is first “absorbed” into the “sponge, and the result is “squeezed” out. While absorbing, message blocks are XORed into a subset of the state. Then it’s transformed into one element. While squeezing, output blocks are read from this element, but alternated with state transformations.
A key aspect of SHA-3 is that it was designed to easily replace SHA-2 in applications that currently use that variant. As such, the transition from SHA-2 to SHA-3 should be analyzed for the required security level and the overhead (refactoring and testing), which greatly depend on the application's structure and architecture.
SHA-3’s authors have proposed additional features like an authenticated encryption system and a tree hashing scheme, but they aren’t standardized yet. Still, it’s the safest hashing algorithm for now.
Useful links library about hashing algorithms
Hashing Algorithm Overview: From Definitions to Usages and Types
Hashing algorithms can be pretty useful. However, IT is a fast-changing industry, and this entropy also extends to hashing algorithms.
MD5, once considered safe, is now completely compromised. Then there was SHA-1, which is now unsafe. The same thing will surely happen to the widely used SHA-2 someday.
To maintain your security standards, you must always follow the newest technologies, especially when you use hashing algorithms for security. It is mandatory to be updated regarding which hashing algorithm is recommended for the protection of sensitive data.
A big part of good security standards, if you're developing web applications, is ensuring that attackers can't reverse engineer or tamper with your JavaScript code.
Start your free Jscrambler trial and secure your code in 2 minutes!
Jscrambler
The leader in client-side Web security. With Jscrambler, JavaScript applications become self-defensive and capable of detecting and blocking client-side attacks like Magecart.
View All ArticlesMust read next
Introduction to Device Fingerprinting
How can we tell a real user apart from an attacker? In this article, we explain a possible way to stop attackers with device fingerprinting.
April 2, 2019 | By Camilo Reyes | 4 min read
How to Store Passwords Safely
Security of users' passwords is one of the most important aspect of developing your web application.
September 22, 2016 | By Jscrambler | 11 min read
