How to Achieve Mongo Replication on Docker
May 21st, 2020 | By Rui Trigo | 5 min read

I noticed the lack of tutorials for setting up Mongo replication on Docker containers and wanted to fill this gap along with some tests to see how a Mongo cluster behaves in specific scenarios.
Replication got to be a part of a bigger migration that brought stability, fault tolerance, and performance to our systems. In this post, we will dive into the practical preparation for that migration.
Tutorial objectives
To improve our production database and solve the identified limitations, our most clear objectives at this point were:
Upgrading Mongo v3.4 and v3.6 instances to v4.2 (all community editions).
Evolving Mongo data backup strategy from mongodump/mongorestore on a mirror server to Mongo Replication (active working backup server).
Merging Mongo Docker containers into a single container and Mongo Docker volumes into a single volume.
Step-by-step
1. Prepare applications for Mongo connection string changes.
When our applications were developed, there was no need to pass the Mongo connection URI through a variable, as most of the time Mongo was deployed as a microservice in the same stack as the application containers. With the centralization of Mongo databases, this change was introduced in the application code to update the variable on our CI/CD software whenever we needed it.
2. Generate and deploy keyfiles
MongoDB’s official documentation has step-by-step instructions on how to set up Keyfile authentication on a Mongo Cluster. Using keyfile authentication enforces Transport Encryption over SSL.
openssl rand -base64 756 > <path-to-keyfile>
chmod 400 <path-to-keyfile>
The keyfile is passed through a keyfile argument on the mongod command, as shown in the next step.
User authentication and role management are out of the scope of this post, but if you are going to use them, configure them before proceeding beyond this step.
3. Deploy existing containers with the replSet argument
mongod --keyfile /keyfile --replSet=rs-myapp
4. Define ports
Typically, in this step, you simply choose a server network port to serve your MongoDB. Mongo’s default port is 27017, but since in our case we had 4 apps in our production environment, we defined 4 host ports.
You should always choose a network port per Mongo Docker container and stick with it.
27001 for app 1
27002 for app 2
27003 for app 3
27004 for app 4
At step 10, after having replication working, we'll only use and expose one port.
5. Assemble a cluster composed of three servers in different data centers and regions
Preferably, set up three servers in different data centers or different regions if possible.
This will allow for inter-regional availability. Aside from latency changes, your system will survive data center blackouts and disasters.
Why 3? It is the minimum number for a worthy Mongo cluster.
1 node: can't have high availability by itself;
2 nodes: no automatic failover — when one of them fails, the other one can't elect itself as primary alone;
3 nodes: minimum worth number — when one of them fails, the other two vote for the next primary node;
4 nodes: have the same benefits as 3 nodes plus one extra copy of data (pricier);
5 nodes: can withstand 2 nodes failure at the same time (even pricier).
There are Mongo clusters with arbiters, but that is out of the scope of this post.
6. Define your replica set members’ priorities
Adjust your priorities to your cluster size, hardware, location, or other useful criteria.
In our case, we went for:
appserver: 10 // temporarily primary
node1: 3 // designated primary
node2: 2 // designated first secondary being promoted
node3: 1 // designated second secondary being promoted
We set the node that currently had the data to priority 10, since it had to be the primary in the sync phase, while the rest of the cluster was not ready. This allowed for continued serving of database queries while data was being replicated.
7. Deploy Mongo containers scaling to N* on a Mongo cluster
(*N being the number of Mongo cluster nodes).
Use an orchestrator to deploy four Mongo containers in the environment, scaling to three.
4 is the number of different Mongo instances.
3 is the number of Mongo cluster nodes.
In our case, this meant having 12 containers in the environment temporarily.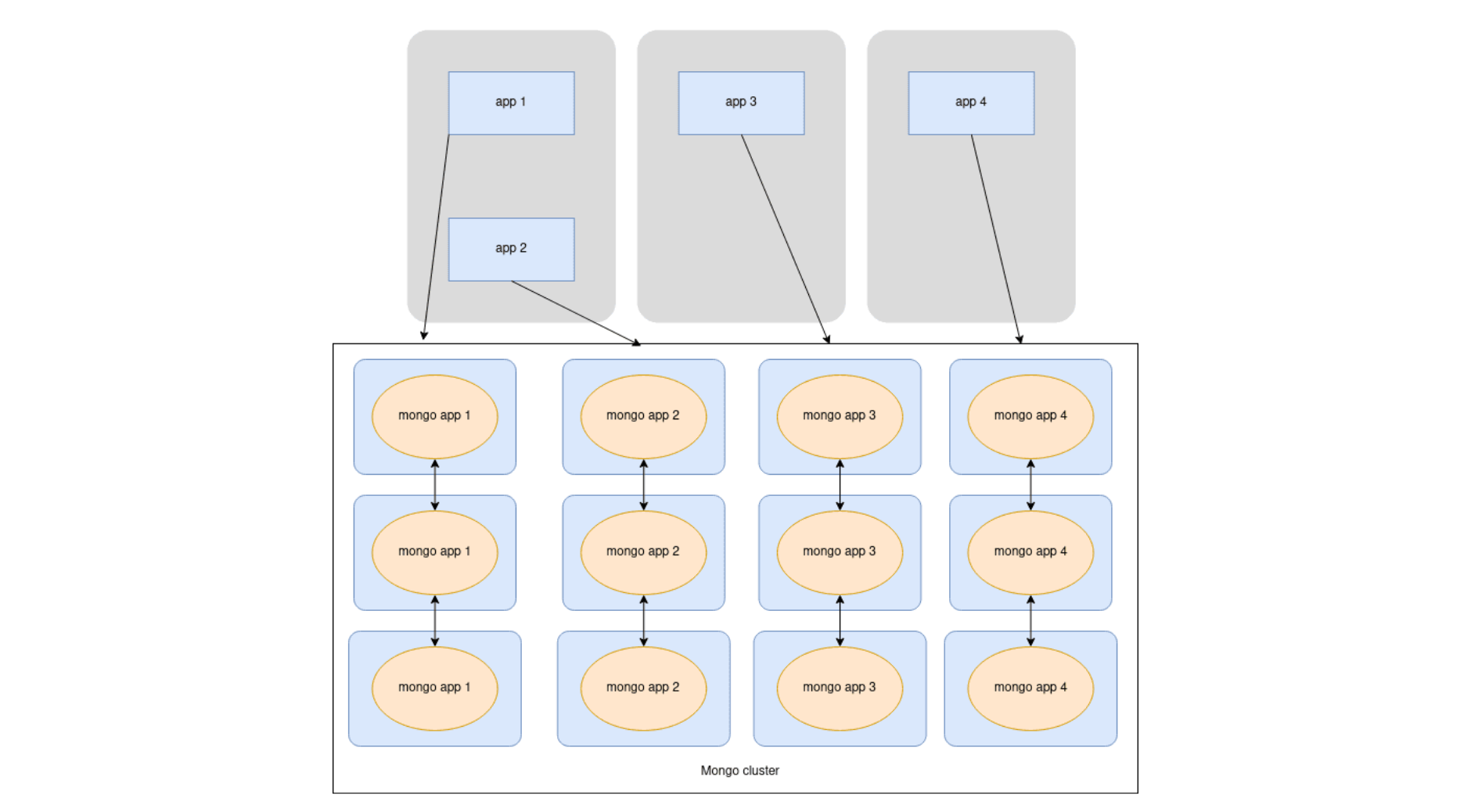
Remember to deploy them as replica set members, as shown in step 3.
8. Replication time!
This is the moment when we start watching database users and collecting data to get synced. You can enter the Mongo shell of a Mongo container (preferably primary) to check the replication progress. These two commands will show you the status, priority, and other useful information:
rs.status()
# and
rs.conf()
When all members reach the secondary state, you can start testing. Stop the primary node to witness secondary promotion. This process is almost instantaneous.
You can stop the primary member by issuing the following command:
docker stop<mongo_docker_container_name_or_d>
When you bring it back online, the cluster will give the primary role back to the member with the highest priority. This process takes a few seconds, as it is not critical.
docker start <mongo_docker_container_name_or_id>
9. Extract Mongo containers from application servers
If everything is working at this point, you can stop the Mongo instance on which we previously set priority to 10 (stop command in the prior step) and remove that member from the replica set, passing its hostname as a parameter.
Repeat this step for every Mongo container you had in Step 4.
10. Migrate backups and change which server they read the data from
One handy feature of MongoDB replication is having a secondary member ask for data to mongodump from another secondary member.
Previously, we had the application and database server perform a mongodump of their data.
As we moved the data to the cluster, we also moved the automated backup tools to a secondary member to take advantage of said feature.
11. Merge data from four Mongo Docker containers into one database
If you only had one Mongo Docker container at the start, skip to step 12.
Besides having simplicity tell us to do this before step 1, we decided to act cautiously and keep apps and databases working in a way as close as they were before until we mastered Mongo replication in our environment.
At this stage, we chose to import data from all Mongo databases into a single Mongo database, the one that contained the most data. When working with MongoDB, remember this line from MongoDB's official documentation:
In MongoDB, databases hold collections of documents.
That means we can take advantage of mongodump --db <dbname> and mongorestore --db <dbname> to merge Mongo data into the same instance (this goes for non-Docker as well).
12. Monitor cluster nodes and backups
When you have merged your databases into the same instance, you will shut down other instances, right? Then, you will only need to monitor the application and perform backups of that same instance.
Don't forget to monitor the new cluster hardware. Even with automatic fault-tolerance, it is not recommended to leave our systems short. As a hint, there is a dedicated role for that called clusterMonitor.
Conclusion
Sharing this story about our database migration will hopefully help the community, especially those not taking full advantage of MongoDB already, to start seeing MongoDB in a more mature and reliable way.
Even though this is not a regular MongoDB replication "how-to" tutorial, this story shows important details about MongoDB’s internal features, our struggle to not leave any details behind, and, again, the benefits of such technology.
That's what I believe technology is for helping humans with their needs.
Jscrambler
The leader in client-side Web security. With Jscrambler, JavaScript applications become self-defensive and capable of detecting and blocking client-side attacks like Magecart.
View All ArticlesMust read next
The 6 Aspects You Must Secure On Your MongoDB Instances
Authentication, authorization, and accounting are key aspects of MongoDB instances. Here, we explore some quick wins to improve their security.
November 25, 2020 | By Rui Trigo | 7 min read
Build Database Relationships with Node.js and MongoDB
Let's dive deeper into MongoDB and understand how relationships work between MongoDB collections in a Node.js server application.
September 10, 2019 | By Connor Lech | 8 min read
